
Alors que les micro-services événementiels deviennent l'une des architectures les plus populaires pour construire des systèmes distribués, cohérents avec les données et à grande échelle, de nombreuses entreprises se retrouvent confrontées à l'équation ultime de l'efficacité du système par rapport à son coût. Être prêt à recevoir un afflux de données à grande échelle à tout moment tout en maintenant le coût de calcul à son niveau le plus bas est un défi auquel nous avons également été confrontés chez Trax. Dans ce blog, nous présenterons notre solution dédiée utilisant certaines des API de base fournies par tous les fournisseurs de cloud. Cette approche innovante nous a permis de minimiser les retards dans le système et d'économiser ~65% du coût de calcul.
Cette innovation de pointe a été présentée par AWS dans un épisode de This is My Architecture.
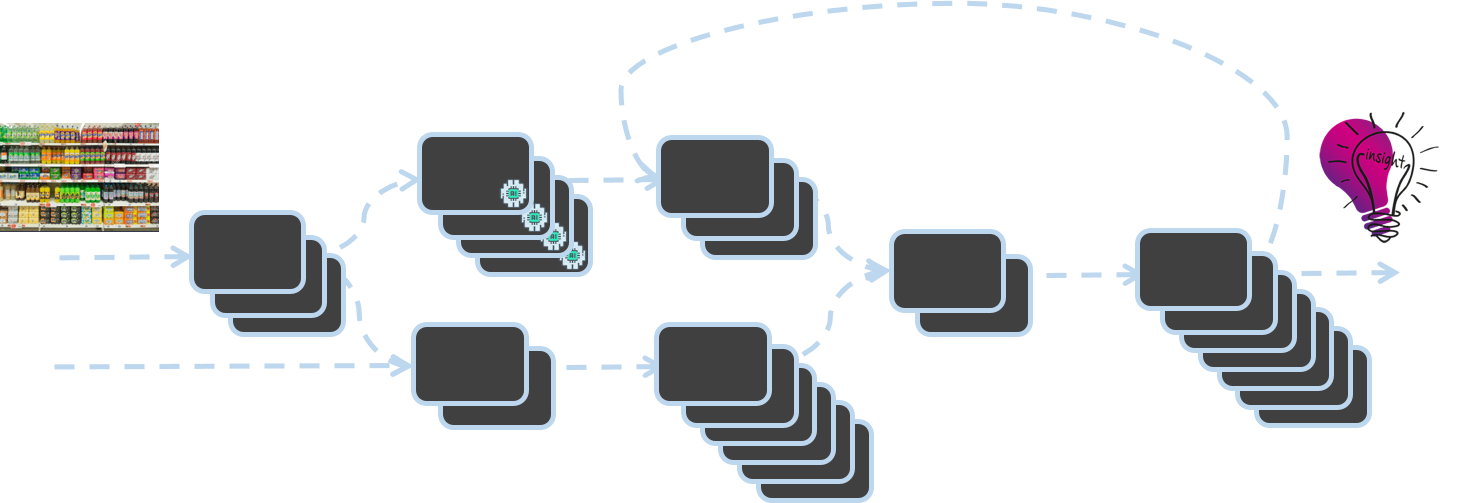
Chez Trax, nous numérisons le monde physique du commerce de détail à l'aide de la vision par ordinateur. La transformation d'images d'étagères individuelles en données et en informations sur l'état des magasins de détail est rendue possible grâce à la "Trax Factory". Construite à l'aide d'une architecture asynchrone pilotée par les événements, l'usine Trax est une grappe de microservices dans laquelle l'achèvement d'un service déclenche l'activation d'un autre service.
L'architecture de l'usine de vision par ordinateur Trax
Ce blog traite de la nécessité d'une infrastructure robuste et évolutive pour prendre en charge l'usine Trax et présente les solutions innovantes développées par les ingénieurs Trax pour ajouter et supprimer de la capacité en fonction de la demande. Découvrez comment Trax a construit un système de traitement des messages pour SNS/SQS basé sur des groupes EC2 à mise à l'échelle automatique, capable d'évoluer toutes les secondes. Notre solution va au-delà de l'analyse classique de la profondeur de la file d'attente en 5 minutes avec CloudWatch, ce qui nous permet de réduire les temps d'arrêt, d'éviter les pertes de données et d'améliorer les niveaux de service globaux.
Le besoin d'échelle
Au début des années 90, Electronic Arts a publié un jeu vidéo de course appelé Need for Speed, qui proposait aux joueurs d'effectuer différents types de courses tout en échappant aux forces de l'ordre lors de poursuites policières.
C'est également à cette époque que les ordinateurs utilisés par diverses entreprises se sont répandus et que les scientifiques et les technologues ont exploré les moyens de mettre la puissance de calcul à grande échelle à la disposition d'un plus grand nombre d'utilisateurs par le biais du partage du temps de travail. C'est ainsi qu'a commencé l'ère de l'informatique en nuage et, avec elle, le défi permanent de l'optimisation de l'infrastructure. Dans ce jeu de "Need for Scale", les équipes d'infrastructure ajoutent et suppriment de la capacité système tout en respectant les lois mises en place par les directeurs d'exploitation, les directeurs financiers et les directeurs de la technologie. Les ingénieurs de Trax, comme leurs homologues d'autres entreprises de technologies basées sur le cloud, doivent optimiser l'échelle tout en améliorant les niveaux de service aux clients, en réduisant les coûts et en conservant la simplicité du système informatique.
Le défi du changement d'échelle chez Trax
Trax dispose de la plate-forme de vision par ordinateur pour le commerce de détail la plus avancée du secteur, avec un système dorsal sophistiqué qui traite des millions d'images d'étagères chaque mois.
L'entrée d'une nouvelle image dans le système est l'un des principaux événements gérés par le backend de Trax. Cet événement déclenche un microservice qui reconnaît les produits dans l'image à l'aide d'algorithmes avancés d'apprentissage en profondeur. Ce processus est asynchrone en ce sens qu'aucun autre micro-service n'attend de réponse de ce service de reconnaissance d'images. Sa tâche se termine lorsqu'il publie un événement une fois qu'il a terminé l'activité de traitement et fourni les résultats. Plusieurs microservices de l'usine Trax travaillent de cette manière, effectuant constamment de nombreuses activités telles que l'assemblage, la géométrie et bien d'autres encore, chacune impliquant différents degrés de complexité informatique.
La transformation de millions d'images issues de multiples projets à travers le monde en informations ciblées et spécifiques pour les clients nécessite une grande puissance de calcul et pèse sur les budgets informatiques.
En règle générale, les décisions relatives à l'extension ou à l'augmentation de la capacité (ajout ou réduction de machines respectivement) sont prises sur la base des mesures de base de la profondeur de la file d'attente fournies par les fournisseurs de services en nuage - par exemple, le nombre de messages dans la file d'attente.
Cette politique d'élargissement se heurte à deux obstacles majeurs :
- Le temps de préchauffage d'une nouvelle machine est d'environ 3 minutes.
- Les fournisseurs de services en nuage indiquent le nombre de messages dans la file d'attente toutes les 5 minutes.
Dans un système complexe comme Trax, où les images entrent dans l'usine en volumes variables et où la charge de chaque service est différente de celle des autres, les informations sur la profondeur de la file d'attente deviennent périmées à des intervalles de 5 minutes. Cela présente le risque non seulement de détecter très tardivement la puissance de calcul requise et de nuire aux accords de niveau de service, mais aussi d'engendrer des coûts supplémentaires en procédant à des ajustements d'échelle.
Illustration de Scaling Monitor utilisant des mesures de capacité prêtes à l'emploi
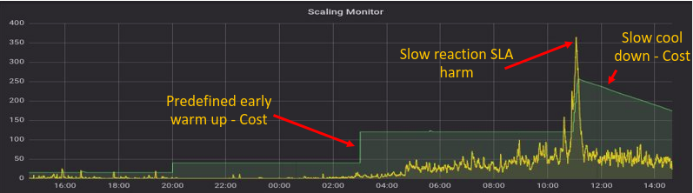
- Le graphique jaune indique le nombre attendu de machines nécessaires compte tenu du nombre total de messages dans la file d'attente et de messages en cours de traitement.
- Le graphique vert représente le nombre réel de machines sur la plate-forme en nuage.
Comme l'indique le graphique, le fait de s'appuyer sur des mesures prêtes à l'emploi pour surveiller l'utilisation de la capacité toutes les 5 minutes entraîne des coûts pour des machines qui ne sont pas utilisées, et nuit aux niveaux de service en faisant fonctionner des machines inadéquates (par exemple entre 10h00 et 12h00 sur le graphique).
Aller au-delà de la profondeur de la file d'attente en tant que mesure d'échelle
La profondeur de la file d'attente a été et continuera d'être un facteur d'influence clé dans les décisions de mise à l'échelle au sein des systèmes basés sur les événements. Mais le fait de s'appuyer uniquement sur la profondeur de la file d'attente en tant que mesure d'échelle crée une approche réactive de l'optimisation de l'infrastructure.
Lorsqu'un message est en attente dans une file d'attente, il prend un temps de calcul précieux que nous préférerions consacrer à un message en cours de traitement par un service. L'idéal est donc de disposer à tout moment d'une certaine puissance de calcul en réserve. Ces systèmes de réserve attendent que de nouveaux messages arrivent dans la file d'attente afin qu'ils puissent être traités immédiatement et sans délai. Naturellement, cette approche proactive est préférable à la nécessité d'ajouter des machines lorsque les messages sont déjà dans la file d'attente et d'augmenter le nombre de machines lorsque la file d'attente est déjà vide. La nécessité de disposer d'une puissance de réserve révèle un fait important : la profondeur de la file d'attente ne dit pas tout.
Ainsi, l'équation correcte pour la mise à l'échelle devrait en fait être la suivante :
Demande = messages en file d'attente + messages en cours de traitement + machines disponibles
Arguments en faveur d'une mesure plus fréquente de la capacité et de la charge
Comme nous l'avons établi dans les sections précédentes, le fait de s'appuyer sur des mesures de mise à l'échelle une fois toutes les 5 minutes n'est pas seulement coûteux, mais entrave également les niveaux de service et la satisfaction des clients. Pour y remédier, nous avons développé un service qui mesure la profondeur de la file d'attente et les messages en cours de traitement toutes les secondes via l'API. En comparant l'ancienne méthode d'échantillonnage à la nouvelle, les améliorations sont très nettes. Dans l'illustration ci-dessous, la demande (ligne jaune) ne dépasse jamais l'offre (ligne verte).
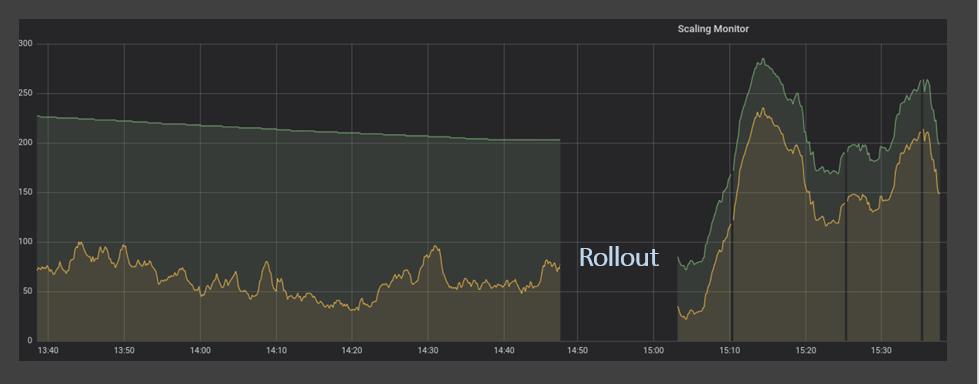
Remarquez que lorsque la demande augmente fortement, l'offre réagit très rapidement, protégeant ainsi nos clients contre des retards de service désagréables.
En outre, cette méthode permet d'aligner étroitement la puissance informatique disponible sur la demande, au lieu de la consacrer à des instances inactives en attente de nouveaux messages.
Une mise à l'échelle prudente
Une mise à l'échelle agressive effectuée de manière incorrecte présente un danger clair et immédiat : la possibilité de mettre à l'échelle des machines qui traitent encore des informations. Dans l'usine Trax, par exemple, les algorithmes basés sur la géométrie prennent généralement plus de temps de traitement que les autres services. Si l'on retire trop tôt de la puissance de calcul à ce service, le message est renvoyé dans la file d'attente. Par conséquent, en plus d'indiquer l'afflux naturel dans le système, les rapports de demande comprennent des messages qui reviennent dans la file d'attente pour la deuxième fois, et peut-être pour la troisième ou quatrième fois. Cette charge peut augmenter considérablement au fil du temps et avoir un impact sur les coûts et les niveaux de service.
Pour éviter cela, nous avons mis en place un mécanisme dans lequel les services qui signalent qu'ils sont encore en train de traiter des messages sont "bloqués". Cela empêche ces instances d'être soumises à des décisions de mise à l'échelle. La plupart des fournisseurs de services en nuage proposent des fonctions qui "protègent" les instances de manière sélective. Une fois que le service a terminé le traitement des messages, il retire son drapeau et retourne dans le pool de ressources informatiques participant au jeu de la mise à l'échelle. Cette capacité garantit que seules les machines inactives sont mises à l'échelle.

Le graphique ci-dessus montre que l'offre et la demande sont en harmonie. Mais remarquez quelque chose que nous n'avions pas vu auparavant. Il y a une nouvelle ligne rouge qui reste toujours proche de l'axe des X. Cette ligne représente le retard de notre système. Cette ligne représente le retard de notre système. En effet, il s'agit du temps pendant lequel le message le plus ancien reste dans la file d'attente avant d'être traité. Le fait que les lignes d'offre et de demande fonctionnent comme elles le devraient et que le délai soit proche de zéro la plupart du temps signifie que les niveaux de service ne sont pas affectés.
Repli robuste
Comme le dit Werner Vogels, directeur technique d'Amazon, "tout échoue tout le temps". Nous avons introduit un changement technologique majeur et développé un service qui mesure la profondeur de la file d'attente et les messages en cours de traitement et qui effectue une opération de mise à l'échelle de notre système. Si ce service tombe en panne, cela signifie que nous perdrons toute capacité de mise à l'échelle - ce dont sont faits les cauchemars des directeurs techniques. Pour éviter cela, un plan de reprise après sinistre est mis en place. Le mécanisme original d'interrogation de la profondeur de la file d'attente toutes les 5 minutes est toujours en place et les deux systèmes fonctionnent en parallèle. Ainsi, si l'un d'eux tombe en panne, les niveaux de service ne sont pas trop affectés.
Les enseignements à tirer
Voici une représentation de notre solution entièrement fonctionnelle lors d'une journée type en milieu de semaine :
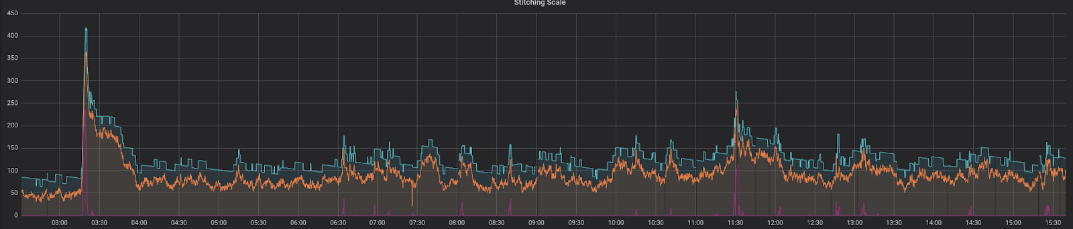
Cela montre une corrélation parfaite entre les machines prévues (ligne orange) et les machines réelles (ligne bleue), avec une quantité suffisante de puissance de calcul disponible. Le temps pendant lequel le message le plus ancien reste dans la file d'attente avant d'être traité (ligne rouge) est constamment faible, avec des pics uniquement pendant de très courtes périodes.
En résumé, la construction d'un mécanisme de mise à l'échelle pour les systèmes asynchrones pilotés par les événements que Trax repose sur quatre piliers fondamentaux :
- Identifier la bonne mesure de la demande: Utiliser la bonne mesure pour contrôler la charge et prendre des décisions de mise à l'échelle.
- Échantillonnage fréquent : Mesurer et prendre des mesures très fréquemment
- Verrouillage de l'échelle : Les systèmes très sollicités ne sont plus concernés par la mise à l'échelle
- Une solution de repli solide : Évitez d'avoir un seul point de défaillance et mettez toujours en place un plan de reprise après sinistre.
Le succès est défini par le degré de satisfaction des responsables de l'application de la loi pour le jeu "Need for Scale" - le directeur financier, le directeur de l'exploitation et le directeur technique - à l'égard de la solution. Le résultat de cette innovation profite à tout le monde :
- (Coût) Économie de ~$10K par mois sur le coût de calcul - en utilisant exactement le nombre de serveurs dont nous avons besoin
- (SLA) Améliorer le SLA en réduisant le temps d'attente dans les files d'attente
- (Simplicité) Unification des files d'attente haute et basse priorité en une seule file d'attente.
Une session sur ce sujet a également été présentée par Michael Feinstein à Reversim 2018. Cliquez sur le bouton de lecture pour visionner la session complète.









